NTU GIL Thesis Analysis (2)
Jessy Chen
/ 2019-05-31
/

data_unnest <- data %>% unnest(abstract_cn_seg)
data_unnest_detail <- data_unnest %>% group_by(title_cn, abstract_cn_seg) %>% summarize(n = length(abstract_cn_seg)) %>% arrange(desc(n)) %>% select(abstract_cn_seg, n, title_cn)## # A tibble: 51 x 3
## # Groups: abstract_cn_seg [30]
## abstract_cn_seg year freq
## <chr> <dbl> <int>
## 1 在 2006 40
## 2 為 2013 40
## 3 聲調 2007 40
## 4 使用 2012 39
## 5 和 2013 39
## 6 與 2012 39
## 7 不同 2009 38
## 8 我們 2008 38
## 9 結構 2008 38
## 10 語言 2012 38
## # … with 41 more rowsdata_year <- data %>% group_by(year) %>% summarize(num = length(author)) %>% arrange(desc(num))
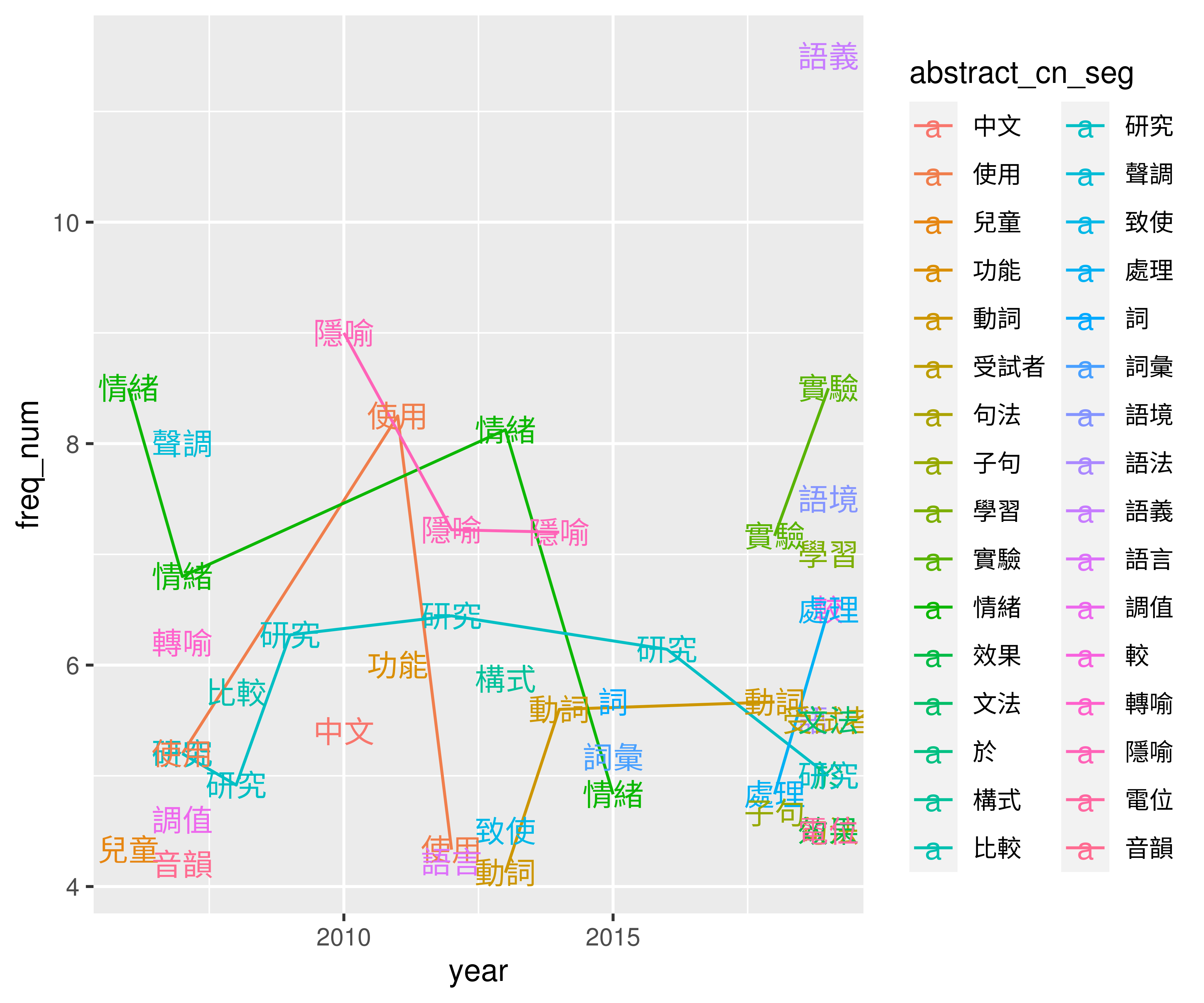
df <- merge(data_unnest_freq, data_year) %>% mutate(freq_num = freq/num) %>% arrange(desc(freq_num, year))
df <- df %>% filter(freq_num > 4 & abstract_cn_seg != "的" & abstract_cn_seg != "在" & abstract_cn_seg != "是" & abstract_cn_seg != "中" & abstract_cn_seg != "了" & abstract_cn_seg != "與" & abstract_cn_seg != "我們" & abstract_cn_seg != "為" & abstract_cn_seg != "及" & abstract_cn_seg != "之" & abstract_cn_seg != "和" & abstract_cn_seg != "也")## year abstract_cn_seg freq num freq_num
## 1 2019 語義 23 2 11.500000
## 2 2010 隱喻 45 5 9.000000
## 3 2006 情緒 51 6 8.500000
## 4 2019 實驗 17 2 8.500000
## 5 2011 使用 33 4 8.250000
## 6 2013 情緒 65 8 8.125000
## 7 2007 聲調 40 5 8.000000
## 8 2019 語境 15 2 7.500000
## 9 2012 隱喻 65 9 7.222222
## 10 2014 隱喻 36 5 7.200000
## 11 2018 實驗 43 6 7.166667
## 12 2019 學習 14 2 7.000000
## 13 2007 情緒 34 5 6.800000
## 14 2019 較 13 2 6.500000
## 15 2019 處理 13 2 6.500000
## 16 2012 研究 58 9 6.444444
## 17 2009 研究 69 11 6.272727
## 18 2007 轉喻 31 5 6.200000
## 19 2016 研究 86 14 6.142857
## 20 2011 功能 24 4 6.000000
## 21 2013 構式 47 8 5.875000
## 22 2008 比較 69 12 5.750000
## 23 2015 詞 34 6 5.666667
## 24 2018 動詞 34 6 5.666667
## 25 2014 動詞 28 5 5.600000
## 26 2019 語法 11 2 5.500000
## 27 2019 受試者 11 2 5.500000
## 28 2019 文法 11 2 5.500000
## 29 2010 中文 27 5 5.400000
## 30 2007 研究 26 5 5.200000
## 31 2007 使用 26 5 5.200000
## 32 2015 詞彙 31 6 5.166667
## 33 2019 於 10 2 5.000000
## 34 2019 研究 10 2 5.000000
## 35 2008 研究 59 12 4.916667
## 36 2015 情緒 29 6 4.833333
## 37 2018 處理 29 6 4.833333
## 38 2018 子句 28 6 4.666667
## 39 2007 調值 23 5 4.600000
## 40 2013 致使 36 8 4.500000
## 41 2019 句法 9 2 4.500000
## 42 2019 效果 9 2 4.500000
## 43 2019 電位 9 2 4.500000
## 44 2006 兒童 26 6 4.333333
## 45 2012 使用 39 9 4.333333
## 46 2012 語言 38 9 4.222222
## 47 2007 音韻 21 5 4.200000
## 48 2013 動詞 33 8 4.125000ggplot(df, aes(year, freq_num, group=abstract_cn_seg, color=abstract_cn_seg)) +
geom_line() +
geom_text(aes(label=abstract_cn_seg))