rvest 練習
爬爬 Mobile01 的 iPhone 版
Andrea
/ 2020-04-16
/

原本想試用 rtweet 搭配 quanteda 的日文斷詞功能整理 twitter
上的武漢肺炎日文資料,然而遲遲無法解決在
RStudio 上可以執行卻不能輸出成 .md 檔的問題,因此決定先回去複習
rvest。
1. 用 rvest 爬資料
以前作業爬過 dcard 和 PTT,這次換個論壇爬爬看。
將 Mobile01 的 iPhone 版前 1000 頁的貼文標題抓下來。
參考資料:http://r3dmaotech.blogspot.com/2016/05/r-rvest.html
require(rvest)
require(dplyr)
# Mobile 01 website links
links <- paste0("https://www.mobile01.com/topiclist.php?f=383&p=", 1:1000)
data <- c()
for(i in 1:length(links)){
url <- links[i]
content <- read_html(url) %>% html_nodes(".u-ellipsis") %>%
html_text()
temp <- iconv(content,'utf8')
data <- c(data, temp)
##sleep time
Sys.sleep(runif(1, 0.5, 0.8))
}
titles <- data[seq(1, length(data), by = 3)]
# Omit NAs
titles <- titles[!is.na(titles)]
2. 寫好 regex 備用
先將可以抓出標題中各型號 iPhone 的 regex 寫好。
i6S <- "[iI](PHONE|Phone|phone)? ?(6s|6S)(?! ?[pP])"
i6SPlus <- "[iI](PHONE|Phone|phone)? ?(6s|6S) ?(PLUS|Plus|plus)"
iSE <- "[iI](PHONE|Phone|phone)? ?(SE|se)(?! ?2)"
i7 <- "[iI](PHONE|Phone|phone)? ?7(?! ?[pP])"
i7Plus <- "[iI](PHONE|Phone|phone)? ?7 ?(PLUS|Plus|plus)"
i8 <- "[iI](PHONE|Phone|phone)? ?8(?! ?[pP])"
i8Plus <- "[iI](PHONE|Phone|phone)? ?8 ?(PLUS|Plus|plus)"
iX <- "[iI](PHONE|Phone|phone)? ?[xX](?! ?[sS])(?! ?[rR])"
iXS <- "[iI](PHONE|Phone|phone)? ?(XS|Xs|xs)(?! ?[mM])"
iXSMax <- "[iI](PHONE|Phone|phone)? ?(XS|Xs|xs) ?(MAX|Max|max)"
iXR <- "[iI](PHONE|Phone|phone)? ?(XR|Xr|xr)"
i11 <- "[iI](PHONE|Phone|phone)? ?(11) ?(?! ?[pP])"
i11Pro <- "[iI](PHONE|Phone|phone)? ?(11) ?(PRO|Pro|pro)(?! ?[mM])"
i11ProMax <- "[iI](PHONE|Phone|phone)? ?(11) ?(PRO|Pro|pro) ?(MAX|Max|max)"
i9_SE2 <- "[iI](PHONE|Phone|phone)? ?(9| ?(SE2|Se2|se2))"
iphones <- c(i6S, i6SPlus, iSE, i7, i7Plus, i8, i8Plus, iX, iXS, iXSMax, iXR, i11, i11Pro, i11ProMax, i9_SE2)
3. 使用 stringr
找出 iPhone 各型號分別有幾篇討論。
library(stringr)
iphones_in_posts <- c()
for (i in seq_along(iphones)){
iphone_in_posts <- sum(str_detect(titles, iphones[i]))
iphones_in_posts[i] <- iphone_in_posts
}
4. 製作表格
library(tibble)
df <- tibble(Model= c("i6S", "i6S Plus", "iPhone SE", "i7",
"i7 Plus", "i8", "i8 Plus", "iX", "iXS",
"iXS Max", "iXR", "i11", "i11 Pro",
"i11 Pro Max", "i9/SE2"),
n = iphones_in_posts)
df <- df %>%
mutate(Order = 1:n()) %>%
arrange(desc(n))
df
## # A tibble: 15 x 3
## Model n Order
## <chr> <int> <int>
## 1 iX 1874 8
## 2 i7 1813 4
## 3 i6S 1442 1
## 4 i8 988 6
## 5 i7 Plus 767 5
## 6 i11 466 12
## 7 i8 Plus 406 7
## 8 i6S Plus 403 2
## 9 iXR 403 11
## 10 iXS Max 385 10
## 11 iXS 336 9
## 12 iPhone SE 334 3
## 13 i11 Pro 182 13
## 14 i11 Pro Max 150 14
## 15 i9/SE2 30 15
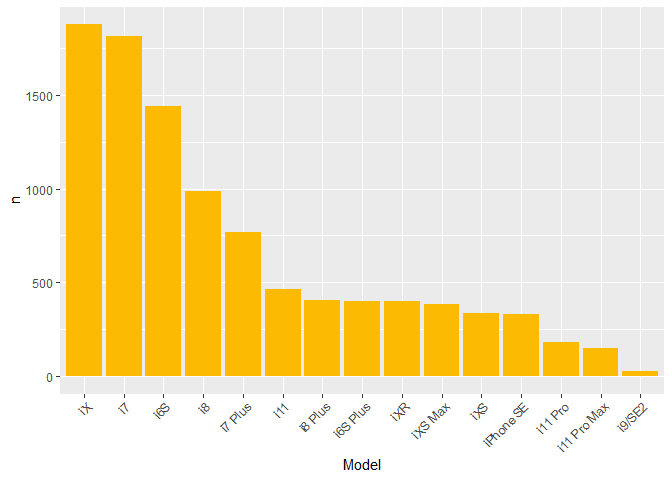
5. Visualization
library(ggplot2)
ggplot(df, aes(x = reorder(Model, -n), y = n)) +
geom_bar(stat = "identity",
fill = "#fcba03") +
xlab("Model") +
theme(axis.text.x=element_text(angle=45, hjust=1))
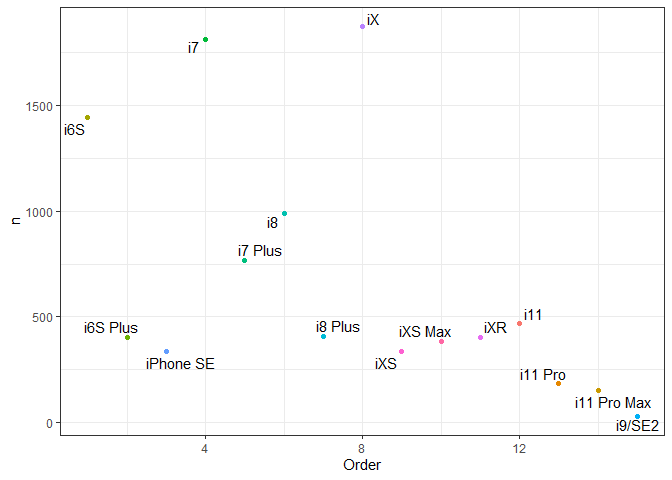
require(ggrepel)
## Loading required package: ggrepel
## Warning: package 'ggrepel' was built under R version 3.6.3
ggplot(df, aes(x = Order, y = n, label = Model)) +
geom_point(aes(color = factor(Model))) +
theme_bw() +
geom_text_repel() +
theme(legend.position = "none")
6. Explanation
從 Mobile01 爬下的前 1000 頁標題資料中可以發現,文章數最多的 iX、i7,以及 i6S 都已經推出一段時間了,所以累積比較多討論。文章數最少的則是最晚推出的 i11 Pro 和 i11 Pro Max,以及預計今年四月中才會發表的 i9 (SE2)。原本預期會看到許多 i9 (SE2) 的討論,但 Mobile 01 上似乎沒有此現象。i6S Plus 和 iPhone SE 雖然是較早期機種,文章數卻比新機少很多,之後預計會爬內文進一步分析。